Wen-Chuang Chou

Passionate about AI with roots in theoretical neuroscience,
I explore LLMs, AI agent, and human mobility—driven by a vision of accessible, everyday AI for all.
AI Agent
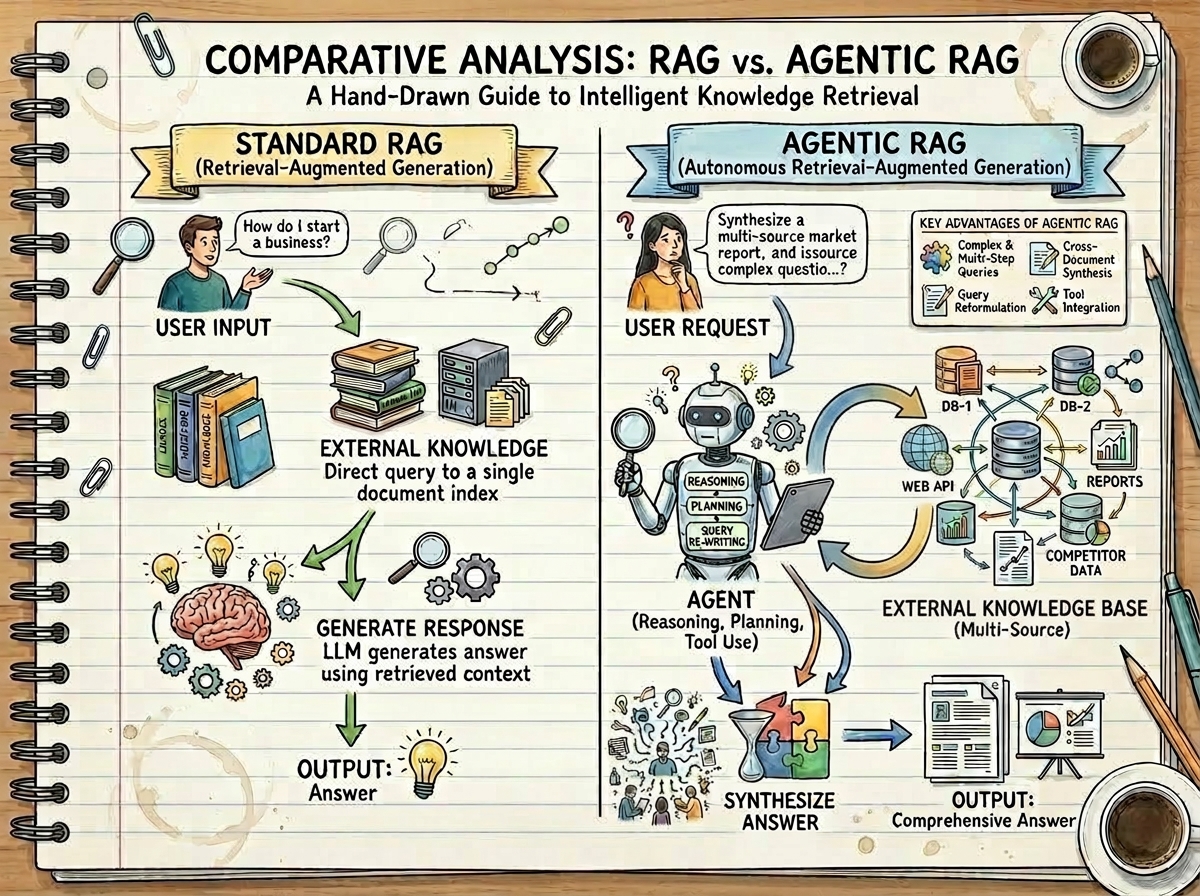
Agentic Retrieval-Augmented-Generation (RAG)
My work on Agentic RAG significantly enhances Large Language Model (LLM) performance for complex information-seeking. This project integrates intelligent AI agents into the RAG pipeline, yielding remarkably more accurate, robust, and contextually rich responses than traditional RAG.
Brief Technique & Impact
I developed an AI agent (using the smolagent package) capable of dynamic decision-making, iterative query reformulation, and intelligent document evaluation. A key contribution is an optimized parallel processing pipeline for efficient FAISS-based vector database creation from technical documentation. This framework fundamentally improves LLM output grounding through advanced reasoning and self-correction.
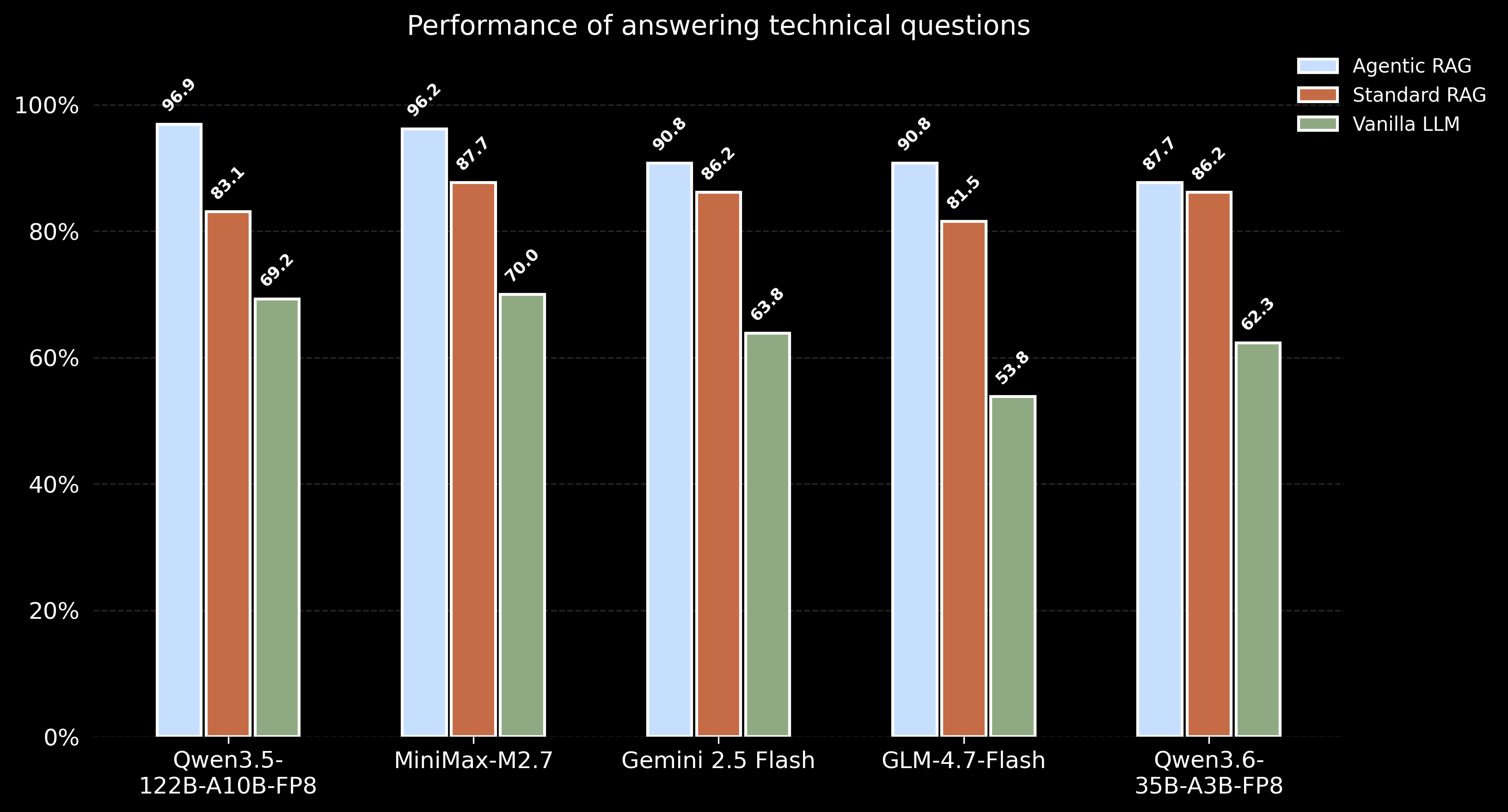
Performance Highlights
Evaluated on a technical Q&A dataset, Agentic RAG consistently demonstrated superior accuracy across various LLMs compared to both Standard RAG and standalone LLM performance:
More details can be found in the project repository on GitHub.
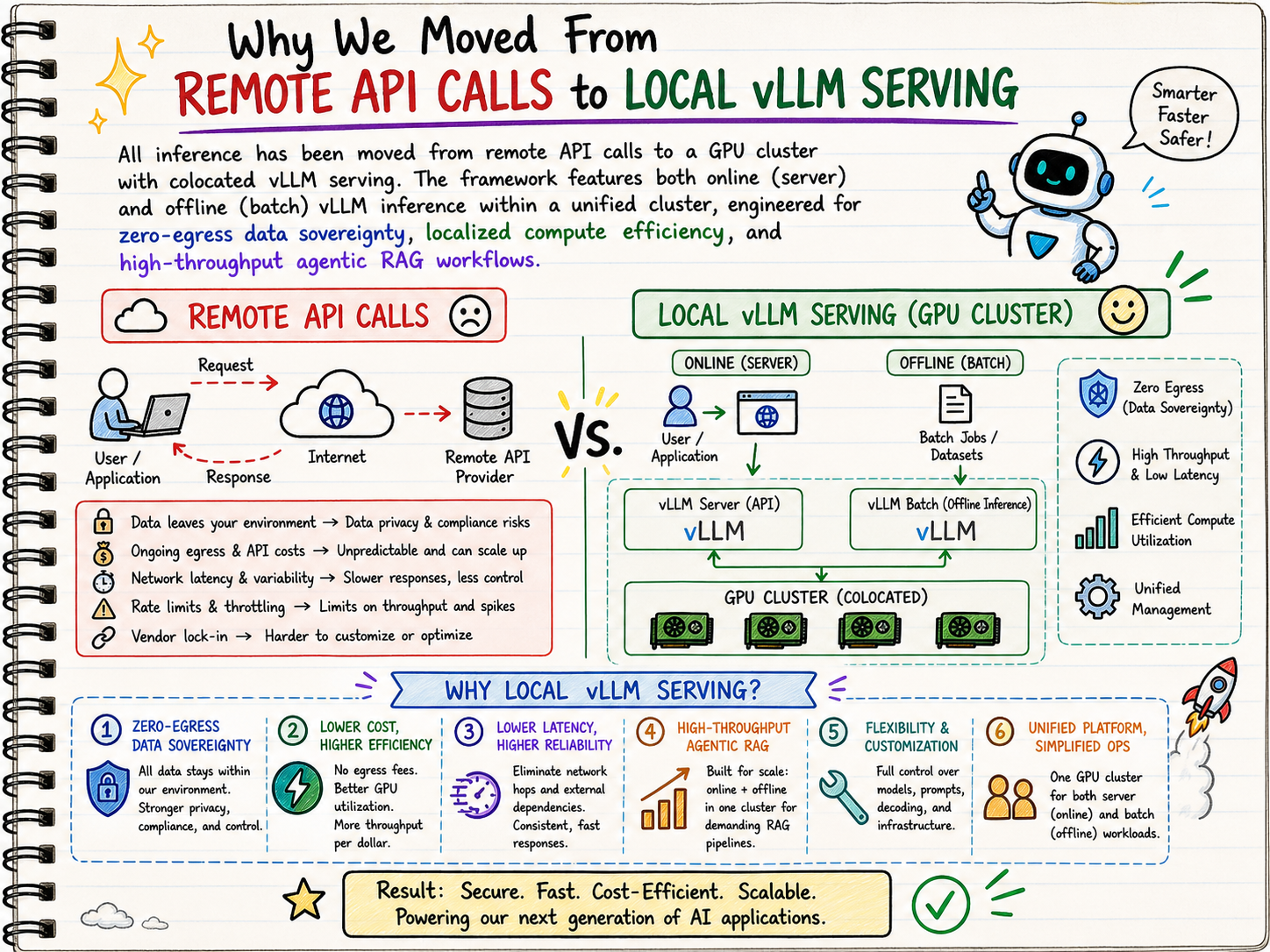
Agentic RAG with Colocated vLLM Inference
This project evaluates Agentic RAG, traditional RAG, and standalone LLM systems on complex technical queries. All inference is successfully moved from remote APIs to a GPU cluster with colocated vLLM serving, ensuring zero-egress data sovereignty.
Brief Technique & Impact
The framework introduces a dynamic agent-based approach for iterative query refinement using smolagents. It runs a three-phase hybrid pipeline combining offline batching and an asynchronous server. This design maximizes GPU utilization and enables concurrent multi-step reasoning, drastically reducing latency compared to traditional API-limited regimes to deliver highly efficient, robust answers.
Performance Highlights
Deploying concurrent Agentic RAG queries on a local vLLM server collapses latency by an order of magnitude. Concurrency and batching transform API-limited pipelines into highly practical, compute-efficient, high-throughput local systems.
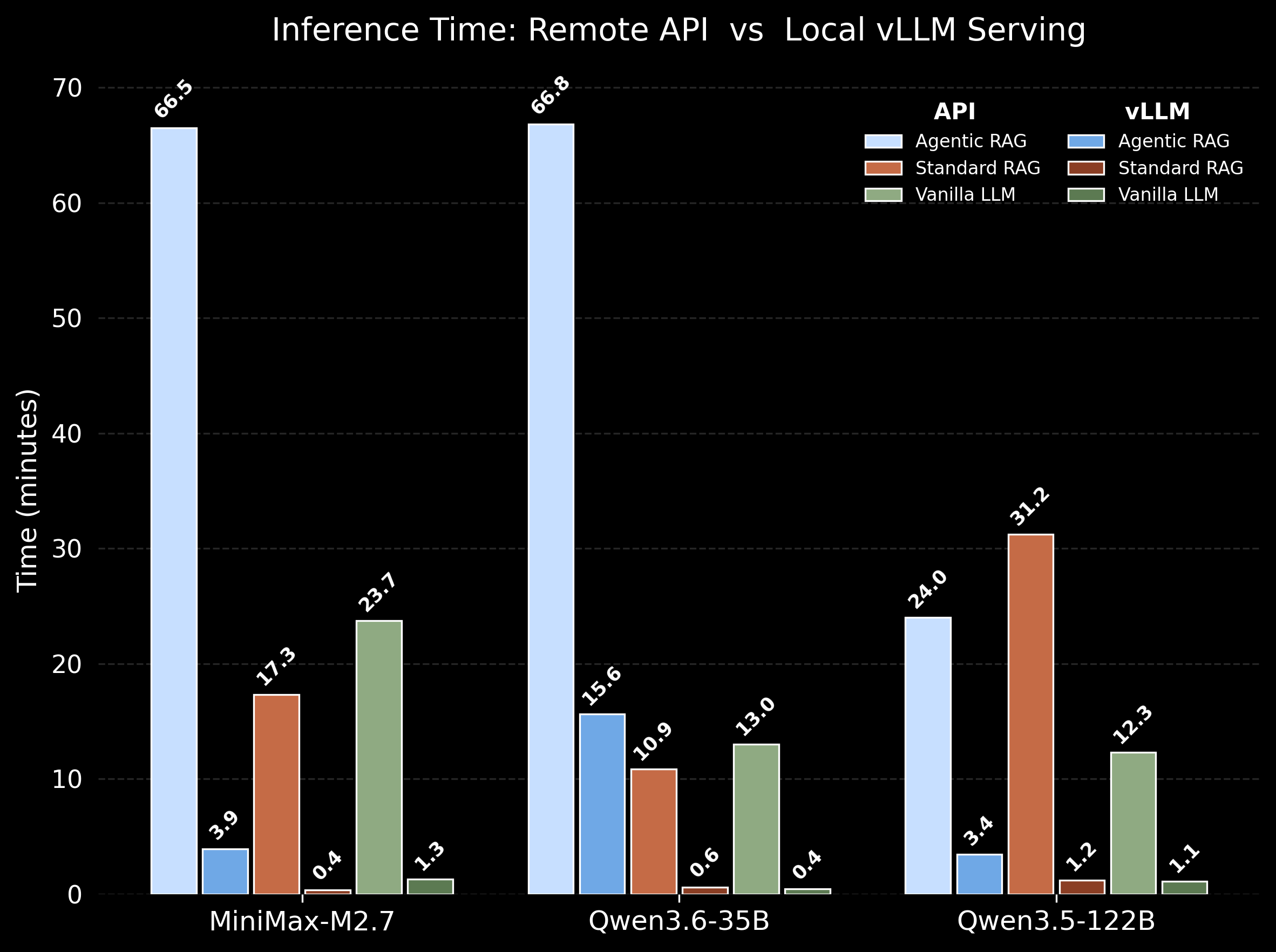 Note: Lower inference times indicate superior system efficiency.
Note: Lower inference times indicate superior system efficiency.
More details can be found in the project repository on GitHub.
Autonomous Multi-Agent Orchestration: GAIA Benchmark
This project implements an advanced autonomous agent system designed to tackle the GAIA (General AI Assistants) benchmark. Unlike traditional chatbots, this agent utilizes a multi-agent orchestration framework to solve complex, multi-modal tasks that require reasoning.
Brief Technique & Impact
Built on the smolagents framework, the system features a hierarchical structure where a Manager Agent coordinates specialized search and vision agents. By delegating data retrieval, it reduces token usage and bypasses access blocks via custom API integration. It features full integration with Langfuse via OpenTelemetry for granular monitoring of agent steps and performance.
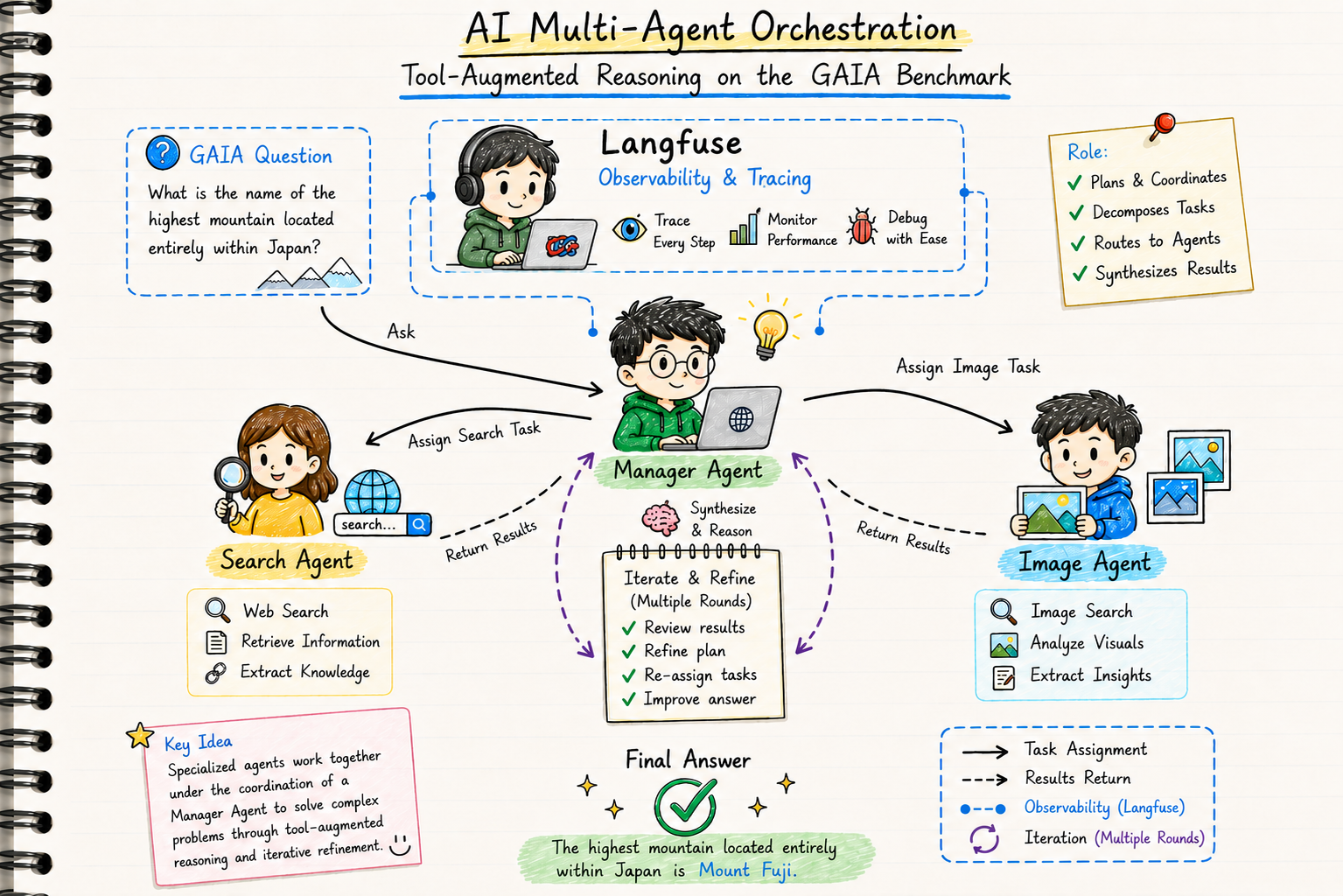
Performance Highlights
The agent achieved a 80% accuracy rate on the GAIA benchmark, significantly outperforming GPT-4’s 14.4% baseline. It leverages dynamic Python-based reasoning and full Langfuse observability to autonomously navigate the web and analyze complex multi-modal datasets.
More details can be found in the project repository on GitHub.