Agentic_RAG
Agentic Retrieval-Augmented-Generation (RAG): AI Agent for self-query and query reformulation
Project Description
This project implements and evaluates Agentic Retrieval-Augmented Generation (RAG), comparing its performance against traditional RAG and standalone Large Language Models (LLMs) when answering technical questions about the Hugging Face ecosystem.
While traditional RAG systems are powerful, they follow a fixed retrieve-then-generate pattern. This project goes further by introducing an agent-based approach that enables dynamic decision-making, iterative query refinement, and adaptive tool use — addressing core limitations of basic RAG when dealing with complex or multi-step queries. The agent intelligently interacts with external knowledge sources, evaluates retrieved content, and refines its strategy based on outcomes, resulting in more accurate, robust, and contextually rich answers. This repository leverages the smolagents package to build the underlying agentic framework.
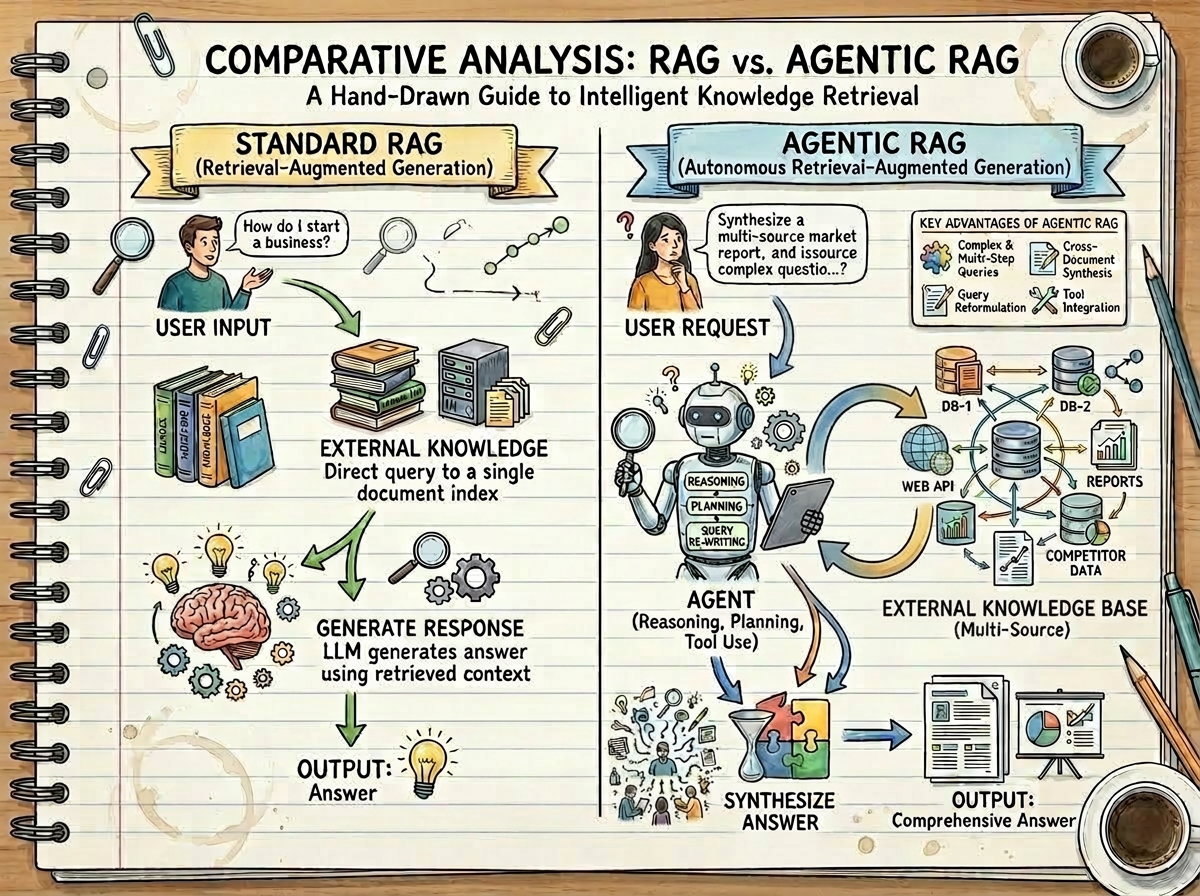
Key Capabilities
| Capability | Description |
|---|---|
| Query Strategy & Refinement | Strategically determines and combines keywords for search queries, iteratively refining them based on retrieval results to optimize relevance and coverage. |
| Iterative Query Refinement | If initial retrieval is insufficient, the agent reformulates queries or expands the number of retrieved documents. |
| Document Evaluation | Assesses the relevance and quality of retrieved information relative to the question before generating an answer. |
| Multi-step Reasoning | Chains together multiple retrieval and generation steps to answer complex questions. |
| Self-Correction & Backtracking | If a generated answer is unsatisfactory, the agent devises and executes alternative retrieval strategies. |
Installation
Prerequisites
- Python 3.12+
- A Gemini API key (free tier available) or Blablador API key
- Git
Steps
- Clone the repository
git clone https://github.com/Wen-ChuangChou/Agentic_RAG.git cd Agentic_RAG - Create and activate a virtual environment (recommended)
python -m venv venv # Windows venv\Scripts\activate # macOS / Linux source venv/bin/activate - Install dependencies
pip install -r requirement.txt -
Configure your API key
Create a
.envfile in the project root and add:GEMINI_API_KEY=your_api_key_here Blablador_API_KEY=your_api_key_here
Usage
There are three main scripts to run the evaluation pipeline and visualize the results.
1. Run the Evaluation — agentic_rag.py
This is the core script. It evaluates and compares three QA systems (Agentic RAG, Standard RAG, and Vanilla LLM) on the Hugging Face technical Q&A dataset, using an LLM-as-judge for scoring. Results are saved as JSON files in the results/ directory, and checkpoints are written to checkpoints/ so long runs can be safely resumed.
python agentic_rag.py
What it does:
- Builds (or loads from cache) a FAISS vector database from the Hugging Face documentation corpus
- Runs Agentic RAG, Standard RAG, and Vanilla LLM inference on the evaluation dataset
- Scores each answer with an LLM judge and saves results to
results/<model_name>_vect<chunk_size>_t<temperature>.json
The model name and chunk size are configurable inside
main()via theconfigdictionary and themodel_namevariable.
Vector database pipeline (utils/vectordb_utils.py):
| Feature | Detail |
|---|---|
| Parallel splitting | Documents split concurrently via ThreadPoolExecutor for large-scale speed-up |
| Batch embedding | Embeds in configurable batches (default 100), merging FAISS shards incrementally to manage memory |
| Thread-safe processing | DocumentProcessor uses threading locks to prevent race conditions |
| Intelligent fallback | Automatically falls back to sequential processing if parallel execution fails |
| Deduplication | Removes duplicate documents by content hash before indexing |
| Persistent caching | Saves/loads the FAISS index from vectordb/ to skip expensive recomputation on repeat runs |
[!TIP] Use a GPU to create the vector store. Embedding generation is heavily compute-bound: on this dataset a GPU completes the full build in ~14 seconds (H100), while a CPU takes more than 23 minutes (AMD 5600x). If a GPU is available, ensure your
torchinstallation is CUDA-enabled — the pipeline will use it automatically.
2. Visualize Performance Scores — visualize_rag_performance.py
Generates a grouped bar chart comparing the mean accuracy (%) of Agentic RAG, Standard RAG, and Vanilla LLM across all JSON result files found in the results directory. The plot is saved as evaluation_scores.png.
python visualize_rag_performance.py
# or specify a custom results directory:
python visualize_rag_performance.py --results_dir path/to/results
Output: results/evaluation_scores.png
3. Visualize Score Distribution — visualize_correct_portion.py
Generates a stacked bar chart showing the proportion of Correct, Partially correct, and Wrong answers for each system type and model. This gives a richer view of answer quality beyond simple accuracy. The plot is saved as score_distribution.png.
python visualize_correct_portion.py
# or specify a custom results directory:
python visualize_correct_portion.py --results_dir path/to/results
Output: results/score_distribution.png
Project Structure
RAG_paper/
│
├── agentic_rag.py # Main evaluation script (Agentic RAG, Standard RAG, Vanilla LLM)
├── visualize_rag_performance.py # Grouped bar chart of mean accuracy scores
├── visualize_correct_portion.py # Stacked bar chart of score distribution
├── requirement.txt # Python dependencies
├── .env # API keys (not tracked by git)
│
├── utils/ # Helper modules
│ ├── agent_tools.py # RetrieverTool for the smolagents CodeAgent
│ ├── blablador_helper.py # Blablador LLM API wrapper
│ ├── checkpoint_runner.py # Checkpointing logic for long evaluations
│ ├── results_manager.py # Save / load evaluation results to JSON
│ └── vectordb_utils.py # FAISS vector database creation & caching (gte-small embeddings, cosine distance, parallel splitting, persistent cache)
│
└─ prompts/ # YAML prompt templates
├── gemini_agent_system_prompt.yaml
├── guide_agent_system_prompt.yaml
└── evaluation_prompt.yaml
Results
Performance was evaluated using the Hugging Face technical Q&A dataset. The results demonstrate that the Agentic RAG approach consistently outperforms standard RAG and standalone LLMs.
Performance Comparison
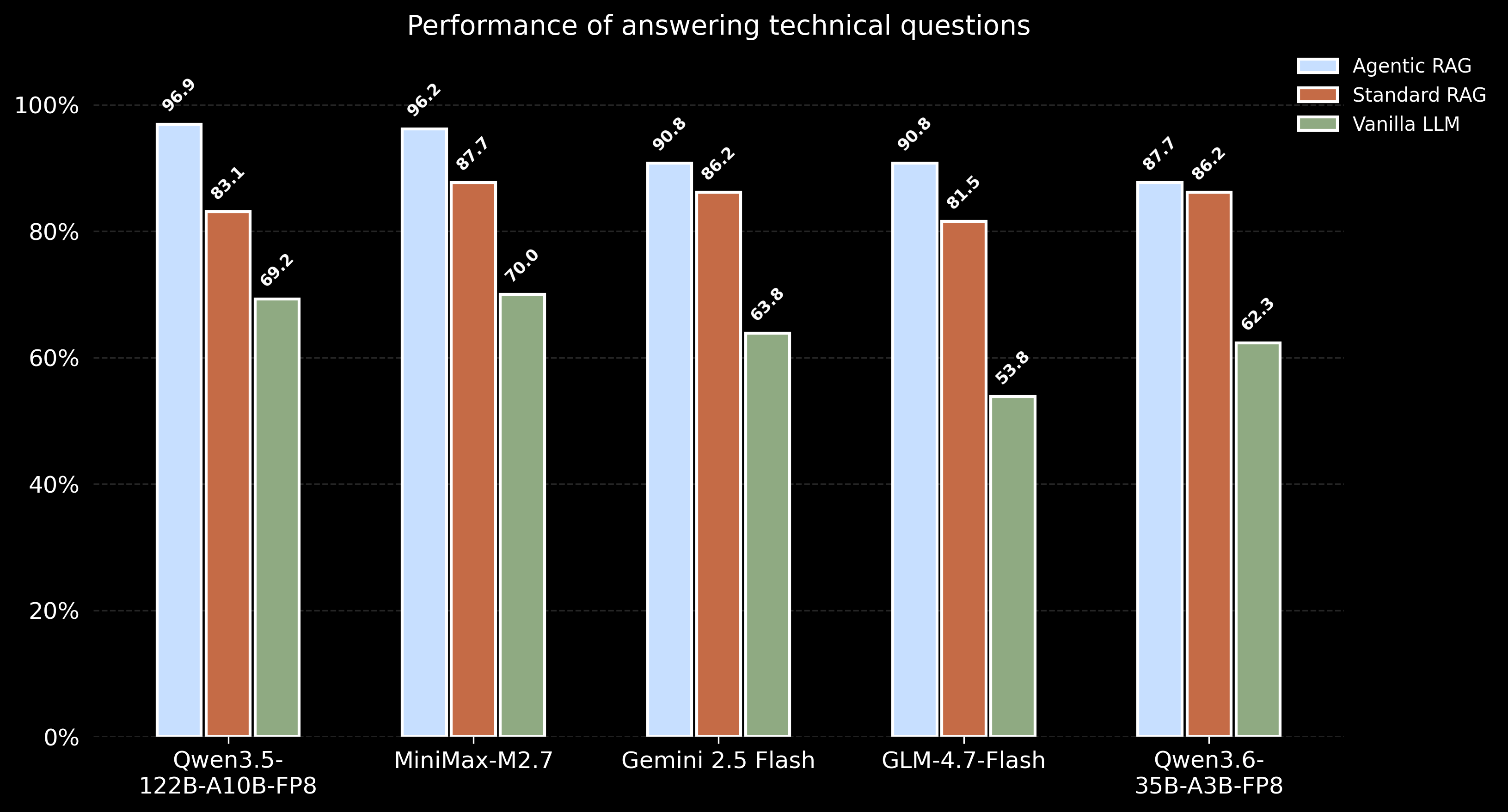
Agentic RAG consistently delivers the highest accuracy across all evaluated models, outperforming Standard RAG by a clear margin and significantly surpassing Vanilla LLM. This indicates that the pipeline design (agentic workflow) has a stronger impact on performance than the choice of base model, and that single-pass retrieval (Standard RAG) is not sufficient for high-quality technical QA.
Score Distribution and Model Strength
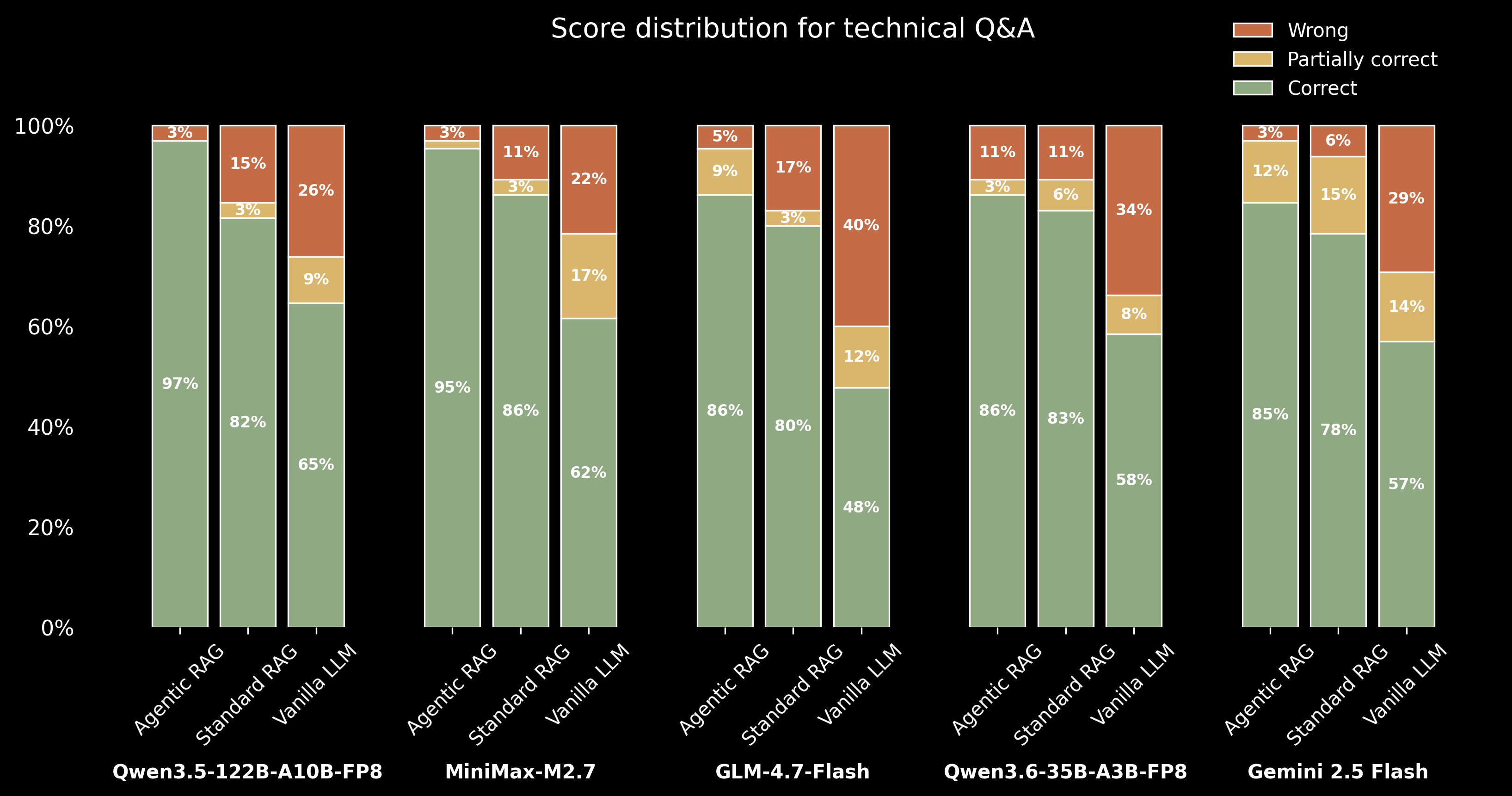
The primary advantage of Agentic RAG comes from drastically reducing incorrect answers, not just increasing partially correct ones. Compared to Standard RAG and Vanilla LLM, it shifts outcomes from “wrong” directly to “correct,” demonstrating that iterative retrieval and reasoning improve answer reliability and suppress hallucinations, rather than merely producing safer or more ambiguous responses.
Extended Project
Private LLM Serving with vLLM: We have successfully implemented a transition from external APIs (such as Gemini or Blablador) to local, HPC-hosted models using vLLM. This dedicated extension significantly improves inference speeds and ensures strict data privacy by keeping sensitive information within a secure, private GPU computing cluster—a critical requirement for production-grade applications.
Future Improvements
To further enhance the performance, efficiency, and security of this Agentic RAG system, the following areas are identified for future development:
-
Comprehensive Agent Telemetry : System prompts are a critical factor in agentic performance. Implementing a robust telemetry system would allow for granular monitoring of agent behavior, enabling systematic comparison of different system prompts and reasoning patterns to identify the most effective configurations.
-
Self-Refining Agent Prompting via Reinforcement Learning : Leveraging Reinforcement Learning (RL) to allow an agent to iteratively refine its own system prompts. The goal is to optimize for factual accuracy while ensuring the agent maintains its existing capabilities. This approach can lead to more efficient retrieval strategies, reducing the number of necessary steps and improving alignment with complex task requirements.