Wen-Chuang Chou

Passionate about AI with roots in theoretical neuroscience,
I explore LLMs, AI agent, and human mobility—driven by a vision of accessible, everyday AI for all.
My AI Portfolio
Engineering advanced AI systems—from autonomous multi-agent systems and scaling reasoning-focused LLMs on multi-node GPU clusters to performance profiling and distilling DeepSeek R1.
- AI Agent
- LLM Benchmarking and Profiling
- LLM Distillation & Fine-Tuning
- Generative AI & Applied Machine Learning
AI Agent
Building intelligent AI agents that dynamically reason, retrieve, and self-correct—from Agentic RAG with colocated vLLM inference to tool-augmented reasoning on the GAIA benchmark.
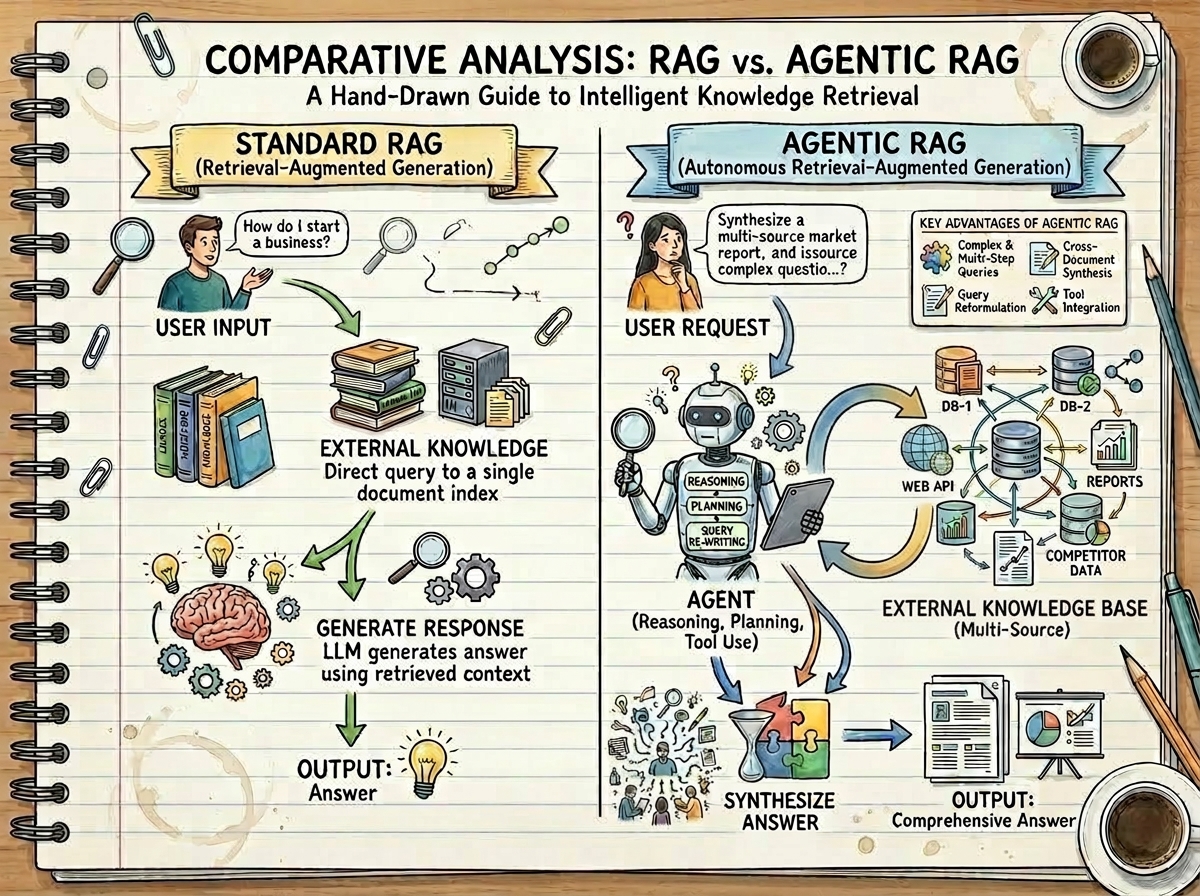
Key projects:
- Agentic RAG — Agent-based retrieval with iterative query refinement, achieving superior accuracy over Standard RAG and standalone LLMs. Details →
- Colocated vLLM Inference — Zero-egress, GPU-cluster deployment with a three-phase hybrid pipeline that collapses latency by an order of magnitude. Details →
- AI Multi-Agent Orchestration — Hierarchical
smolagentsframework with Langfuse telemetry; achieves 80% accuracy on GAIA benchmark, outperforming GPT-4’s 14.4% baseline. Details →
Explore all AI Agent projects →
LLM Benchmarking and Profiling
Systematic performance analysis of Transformer architectures—benchmarking FP32 vs. BF16 mixed precision and profiling compute- vs. memory-bound operations in self-attention.
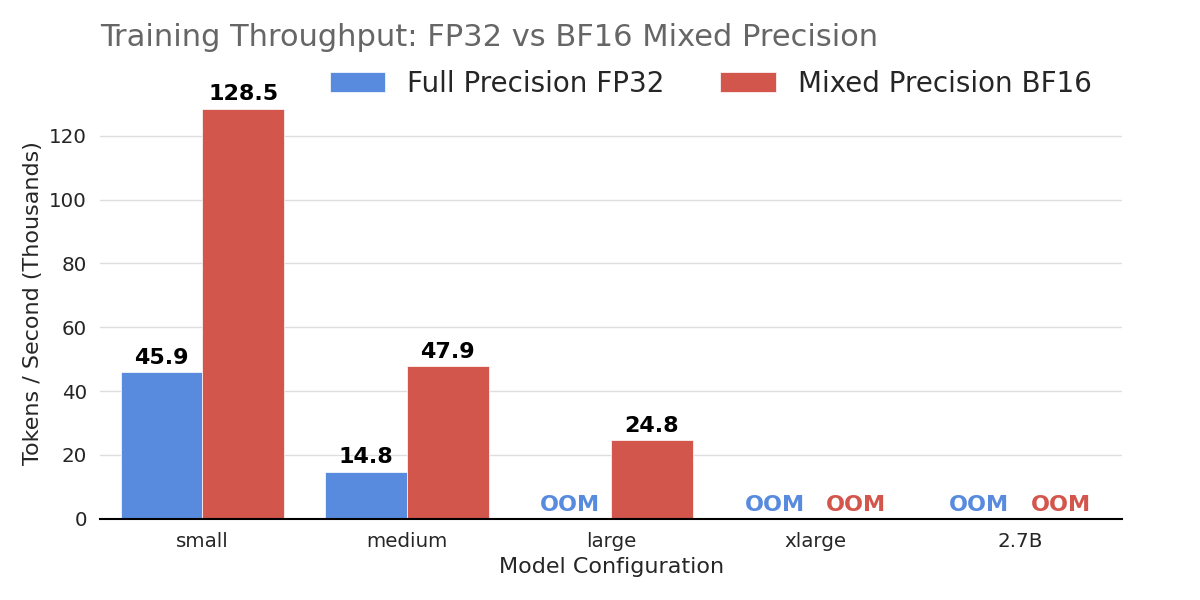
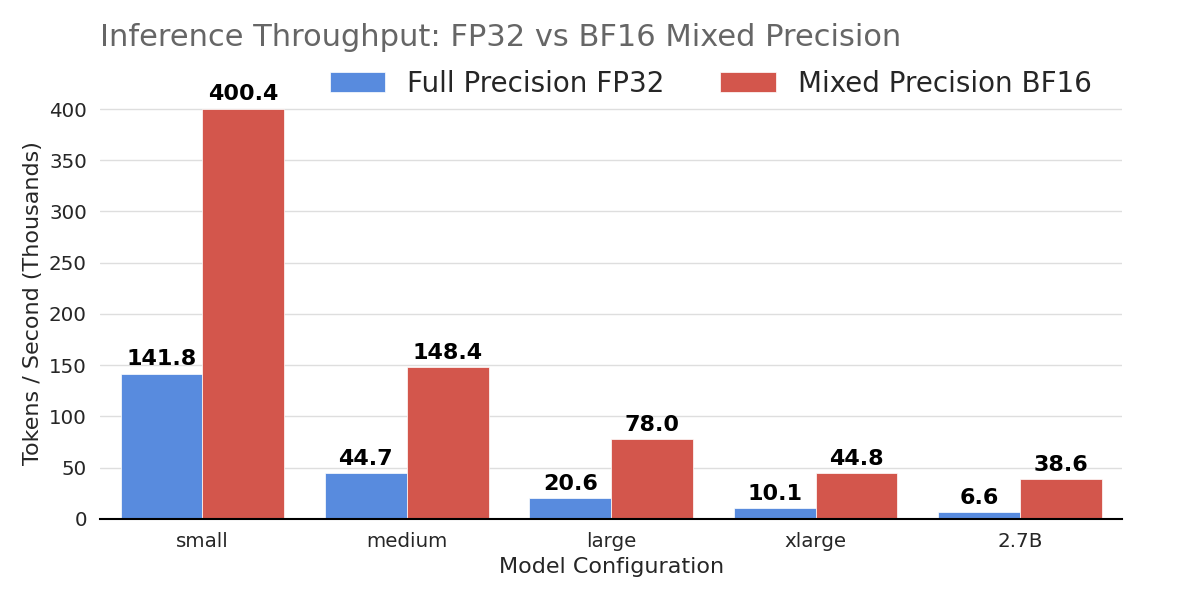
Key projects:
- FP32 vs. BF16 Benchmarking — BF16 mixed precision delivers up to 6× inference throughput and unlocks training of larger architectures that fail under FP32. Details →
- Arithmetic Intensity Profiling — Reveals why MatMul completes in half the time of Softmax despite 25.6× more FLOPs, demonstrating the compute-bound vs. memory-bound paradigm. Details →
Explore all Benchmarking projects →
LLM Distillation & Fine-Tuning
Advanced post-training and fine-tuning across large language models—from distilling DeepSeek R1 on multi-node HPC to instruction-tuning Llama 3.

Key projects:
- DeepSeek R1 Distillation — Boosted Qwen2.5-Math-7B accuracy from 13.3% to 56.7% on AIME 2024 via SFT + GRPO across 8 H100 GPUs. Details →
- Llama 3 Sentiment Analysis — Fine-tuned Llama 3.1–8B achieving 81.49% accuracy on MTEB tweet sentiment. Details →
Explore all LLM Distillation & Fine-Tuning projects →
Generative AI & Applied Machine Learning
Developing and fine-tuning generative models for image synthesis, as well as applying advanced deep learning architectures to real-world predictive modeling and audio processing tasks.


Key projects:
- Stable Diffusion LoRA — Fine-tuned SD v2 with LoRA for Naruto-style generation, with 77% training time reduction via multi-GPU. Details →
- Bike Traffic Prediction — Graph Attention Networks for urban traffic forecasting; 2nd place at BTW 2023. Details →
- Speaker Identification — Transformer/Conformer encoders achieving 91.8% accuracy. Details →
- Anime Face Generator — Diffusion probabilistic model trained on 71k anime faces. Details →
Explore all Generative AI & Applied Machine Learning projects →